- Technology
- 技術紹介
大量データ高速処理製品 「ESPERiC」で採用しているインメモリ・カラムナー技術の概略を紹介します。この技術は日本国内・海外で特許化されています。
図1は、上段左が元の表データの内容、下段がそれに対応するメモリ上のデータ構造を表しています。メモリ上のデータ構造は3つの1次元配列で構成されます。この構造は実行時のワーキングセットが少なく、メモリのキャッシュを有効に使えます。また、値リストにはユニークな値が格納されるのでデータの圧縮効果があります。値リストの大きさはカーディナリティによります。ESPERiCはカーディナリティが大の場合でも速度は大きく低下しません。
※ カーディナリティとは 値の種類の数。その項目の値が「男か女か」ならカーディナリティは2。氏名などは大きくなります。数値データなどは巨大になることもあります。一般にDBはカーディナリティ大の場合に速度は低下します。
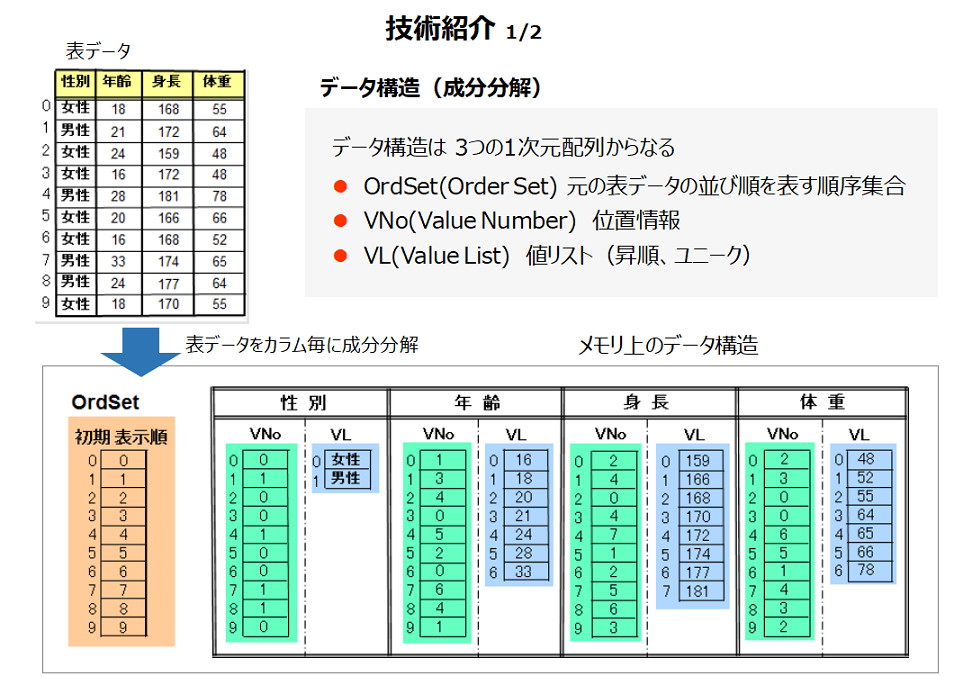
インデックスがデータ構造に自然な形で組み込まれているので、インデックス設計が不要になり、データベースの構築が効率的に行えます。スキーマ設計も不要です。
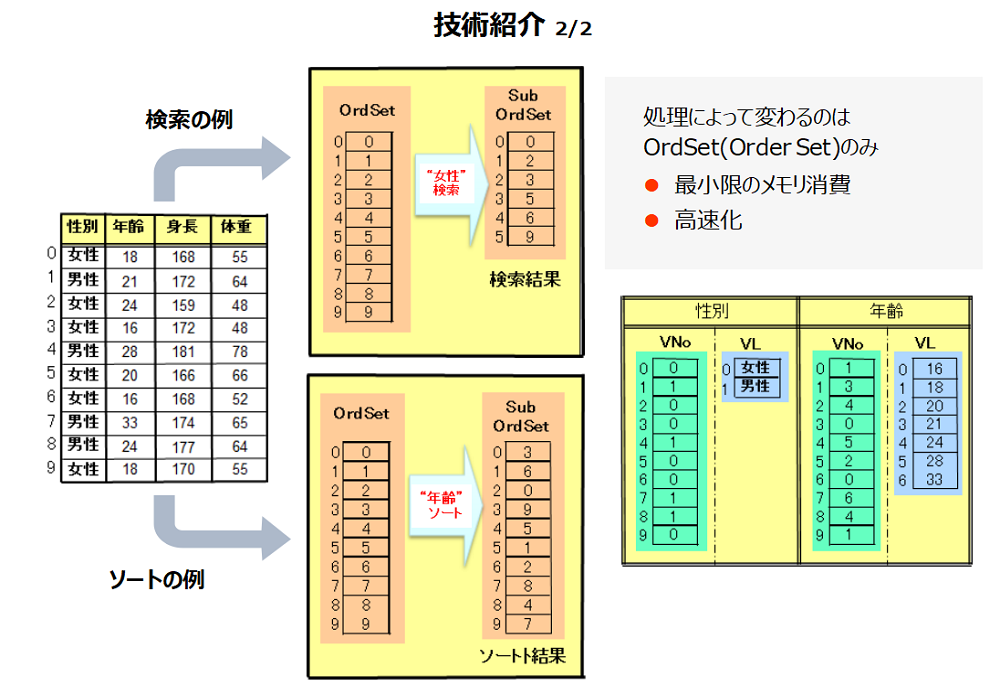
図2に 検索とソート処理の例を示します。処理によって変わる部分はOder Setのみであり、最小限のメモリ消費ですみ、高速処理が可能です。
検索は以下の手順で処理されます。
- 性別のVLで女性を探す。結果は0。
- 性別のVNoで0の値を探す。結果は0と2と3と5と6と9。
- 検索結果のOder Setを作成する。
ソートは以下の手順で処理されます。
- Order Set の全て(0から9)をソートの対象にし、年齢のVNoから取り出す。
- VLの先頭の値16を取り出し、VNoから一致するものを探す。結果は3と6。
- VLの次の値18を取り出し、VNoから一致するものを探す。結果は0と9。
- 3.をVLの最後まで繰り返す。
- 結果、昇順に並んだOrder Set が作成される。
この様に処理は非常に軽いものであることがわかります。また、ESPERiCは検索やソートなど多くの処理をマルチスレッドでパラレル実行します。CPUのコア数が多いほど処理時間は短くなります。
- Why not start with the 6 month free offer?
- まずは6ヶ月のトライアルから!
フリー版をダウンロード